今天我們要來實作GRU,在前一天的內容中,我們講到了GRU相較於LSTM的優勢就在於他的執行時間以及記憶體的使用獲得了縮短,因此我們今天就要來透過實作來實際看看縮短的效果。
為了保證公平,今天的實作同樣會使用之前RNN實作以及LSTM實作使用的stock.csv,沒看過的讀者可以先回頭看看喔。先來看一下模型建構函式應該怎麼修改,修改的方式其實也很簡單,只需要將LSTM改成GRU就好,GRU我們同樣使用kearas.layers中的套件。函式程式碼如下:
def build_model():
model = Sequential()
model.add(LSTM(input_shape = (10, 3), units = 256, unroll = False))
model.add(Dense(units = 1))
model.compile(loss = "mse", optimizer = "adam", metrics = ["accuracy"])
return model
接下來介紹計算運行時間的方法,筆者這邊使用了time函式庫中的process_time函式,這個函式可以紀錄當下的CPU time。我們只需要在呼叫train_model函式的前後使用process_time去紀錄再相減,就可以知道訓練所花費的CPU time了。下方是GRU所預測的結果,可以看見又比起一般RNN和LSTM更為準確了一些。
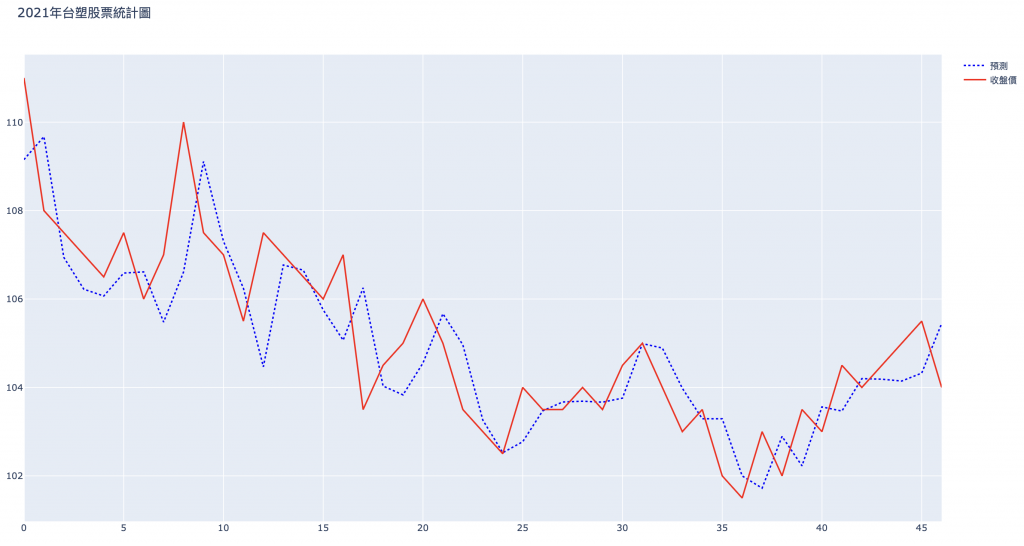
筆者這邊得出的結果是LSTM花費31.233的CPU time、GRU花費25.441的CPU time,可以看見GRU的確有較快速的運算,而且這還是在我們的資料還不大的情況下,若是換成更大的資料集,花費的時間會更明顯的短。


 iThome鐵人賽
iThome鐵人賽